The Importance of Server-Side Tracking in Online Data Analysis

Server-side tracking today: why it has become central to analytics, advertising, and data quality
In today’s digital ecosystem, shaped by privacy-first browsers, platform-side restrictions, stricter regulatory attention, and a growing dependence on incomplete signals, server-side tracking has become one of the most relevant evolutions for companies that take performance marketing, web analytics, and data quality seriously.
Today, the issue is no longer just the reduction of third-party cookies. The real challenge is broader: denied consent, ad blockers, browser limitations, statistical modeling, signal loss, and increasing difficulty in reading attribution, funnels, and the real impact of campaigns with confidence.
In this context, continuing to rely exclusively on client-side tracking means accepting a growing share of partial measurement. Server-side is not a technical shortcut and it does not replace compliance, consent, or strategy. It is, however, an architectural choice that helps build a data foundation that is more governed, more readable, and more useful for business decision-making.
At HT&T, we address these issues by integrating measurement, advertising, data governance, and digital infrastructure through an approach that combines web analytics, media planning, data warehouse, and a critical reading of performance.
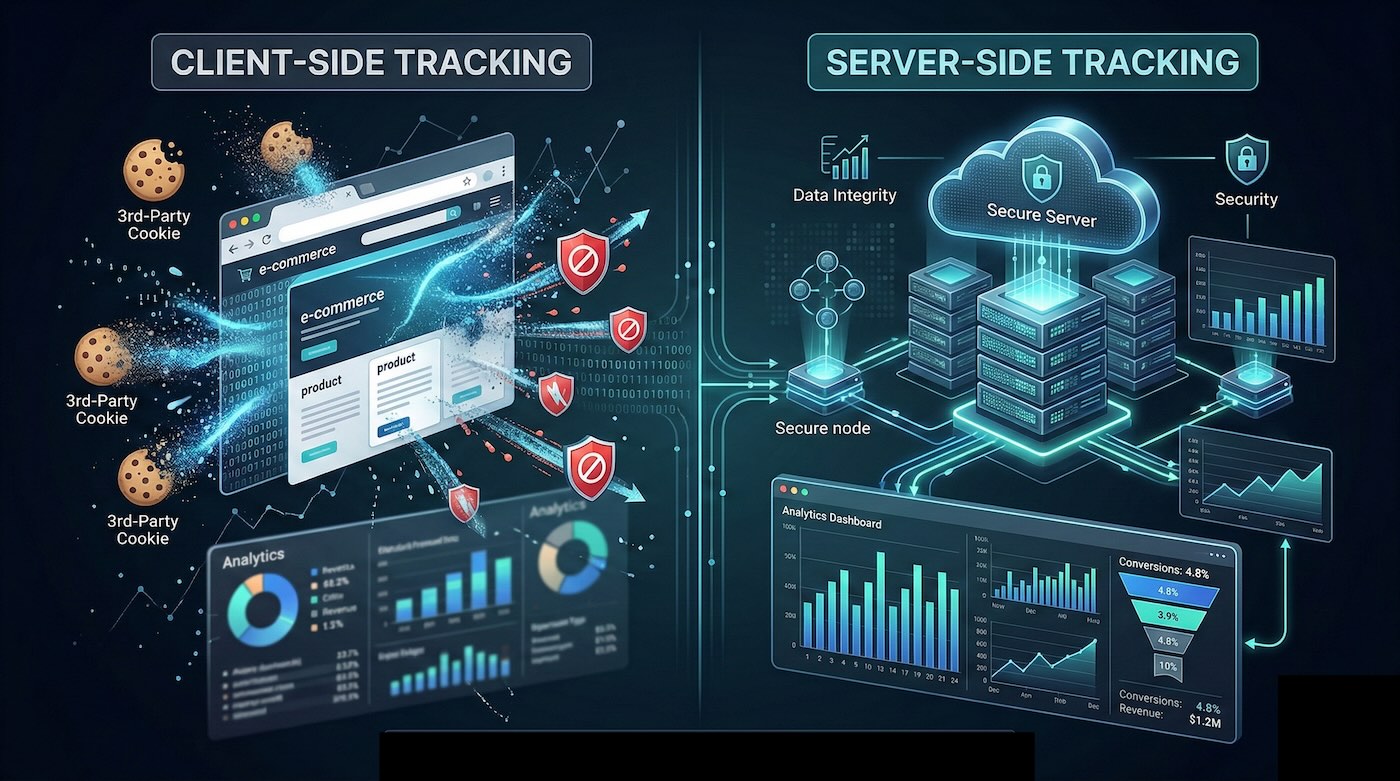
In this article, we take a practical look at:
What is client-side tracking?
Client-side tracking is based on scripts running directly in the user’s browser. When a visitor interacts with a website or application, data is sent from the browser to analytics or advertising platforms such as Google Analytics, Google Ads, Meta Ads, and other measurement systems.
This model mainly relies on JavaScript, marketing tags, and browser cookies, which make it possible to identify sessions, users, events, and conversions throughout the digital journey.
For years, this was the dominant model because it was relatively simple to implement, easy to extend, and often sufficient to understand user behavior. Today, however, the context has changed structurally.
Limitations of client-side tracking in a privacy-first, consent-first ecosystem
Over the last few years, the digital ecosystem has shifted toward a privacy-first model. Browsers have introduced increasingly strong protections against invasive tracking, while platforms and regulations have made data processing and consent management more rigorous.
This means client-side tracking has become more fragile. Some signals never arrive, some are blocked, some are shortened in duration, and some become less reliable over time. It is therefore no longer accurate to frame the issue in simplistic terms such as “cookies used to exist and now they do not.” The real point is that the browser is no longer a neutral, fully controllable environment for measurement.
The consequences directly affect:
- conversion attribution
- advertising optimization
- funnel analysis
- audience building and activation
- the reliability of reporting for decision-making
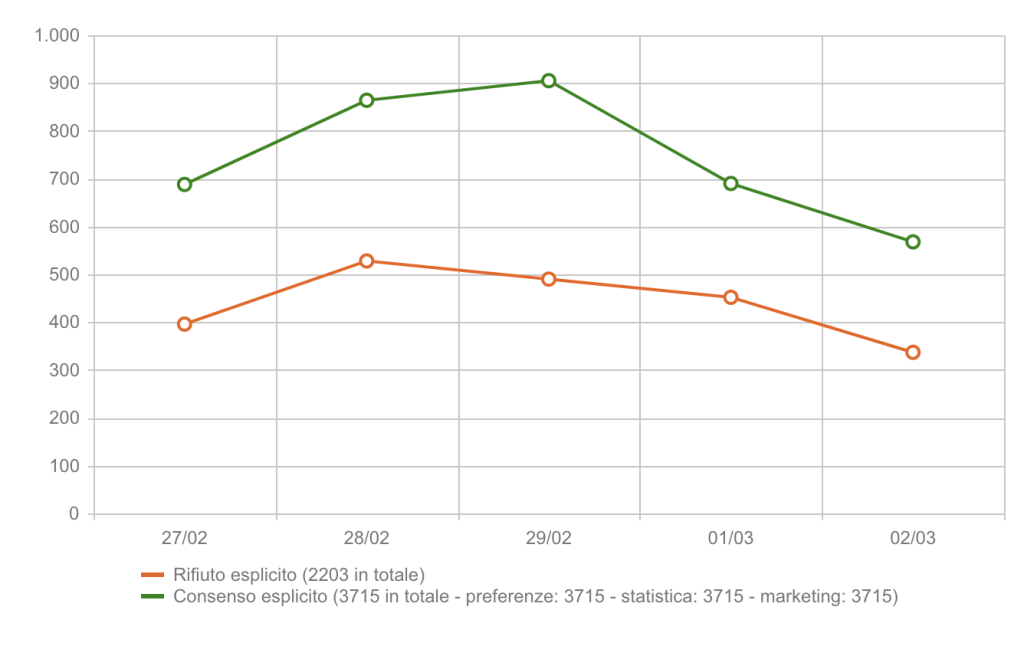
How much do denied consents affect data?
The impact of denied consent can be highly significant. Market benchmarks show that acceptance rates are neither stable nor uniform: in many European contexts, opt-in rates may remain around or below 50%, while in other projects they can rise substantially depending on brand strength, banner UX, and the structure of the requested purposes.
Usercentrics, for example, points out that in some cases an acceptance rate of around 50% may even be below the relevant benchmark. The same company also highlights a more recent trend: nearly half of users say they click “accept all” less often than they did three years ago. This confirms that consent acceptance cannot be treated as a fixed constant.
In practical terms, a meaningful share of real user behavior may never enter directly observed measurement. And when analytics and advertising operate on a partial data foundation, attribution, audience building, and media optimization become less reliable.
Can machine learning compensate for data loss?
Modern analytics and advertising platforms increasingly use predictive models to estimate missing data caused by cookie rejection, ad blockers, or browser limitations. But this needs to be stated clearly: it is a statistical compensation, not direct observation.
Modeled data is useful, and often necessary, but it remains a probabilistic projection based on historical patterns, correlations, and aggregated signals. It works better when the context is stable. It becomes less reliable when channels, messaging, audience composition, media pressure, or incoming signal quality change.
Taking Google Analytics 4 as a reference, though the same principle applies to other advanced systems:
Use of available data
Observed signals are used to reconstruct behavioral patterns and estimate missing sessions, users, and conversions.
Predictive models
Statistical and machine learning models estimate unobserved data using historical behavior and aggregated signals.
Filling information gaps
Modeling attempts to compensate for information loss caused by rejection, blocking, or browser-side restrictions.
Continuous recalibration
Models are updated over time, but they still depend on the quality and quantity of the available input signals.
The structural limit of modeling
The limitation is not theoretical but operational: the more modeled data increases, the greater the potential distance between representation and reality. And when the modeled signals are the same ones used for attribution, bidding, or remarketing, the impact spreads across the entire marketing system.
- less stable cross-channel attribution
- lower visibility on the real value of conversions
- less accurate audiences
- media optimizations increasingly based on incomplete patterns
The issue is therefore not that “modeling is wrong.” The real issue is different: if the business optimizes on a data foundation that is too partial, decision quality weakens. That is also why server-side tracking should be connected not only to tracking itself, but to a broader view of measurement and budget allocation, as we explore in our article on ROAS, AI, and real profit.
The point is not to collect as much data as possible, but to reduce the distance between observed data, modeled data, and business decisions.
Server-side tracking and Consent Mode v2 are not the same thing
One of the most common mistakes is to confuse server-side tracking with Consent Mode v2. In reality, they solve different problems and operate at different levels.
Consent Mode v2 is designed to communicate the user’s consent status to Google platforms and regulate tag behavior accordingly. Server-side tracking, on the other hand, is an architecture for collecting, transforming, and routing data in an environment controlled by the business.
In practice, Consent Mode governs the relationship between consent and tag activation, while server-side governs the technical quality of data transit, parameter filtering, enrichment with internal data, deduplication, and routing to multiple platforms.
Separately, they serve different purposes. Together, they can contribute to more robust and coherent measurement that is less dependent on the browser alone.
Direct impact on advertising campaigns
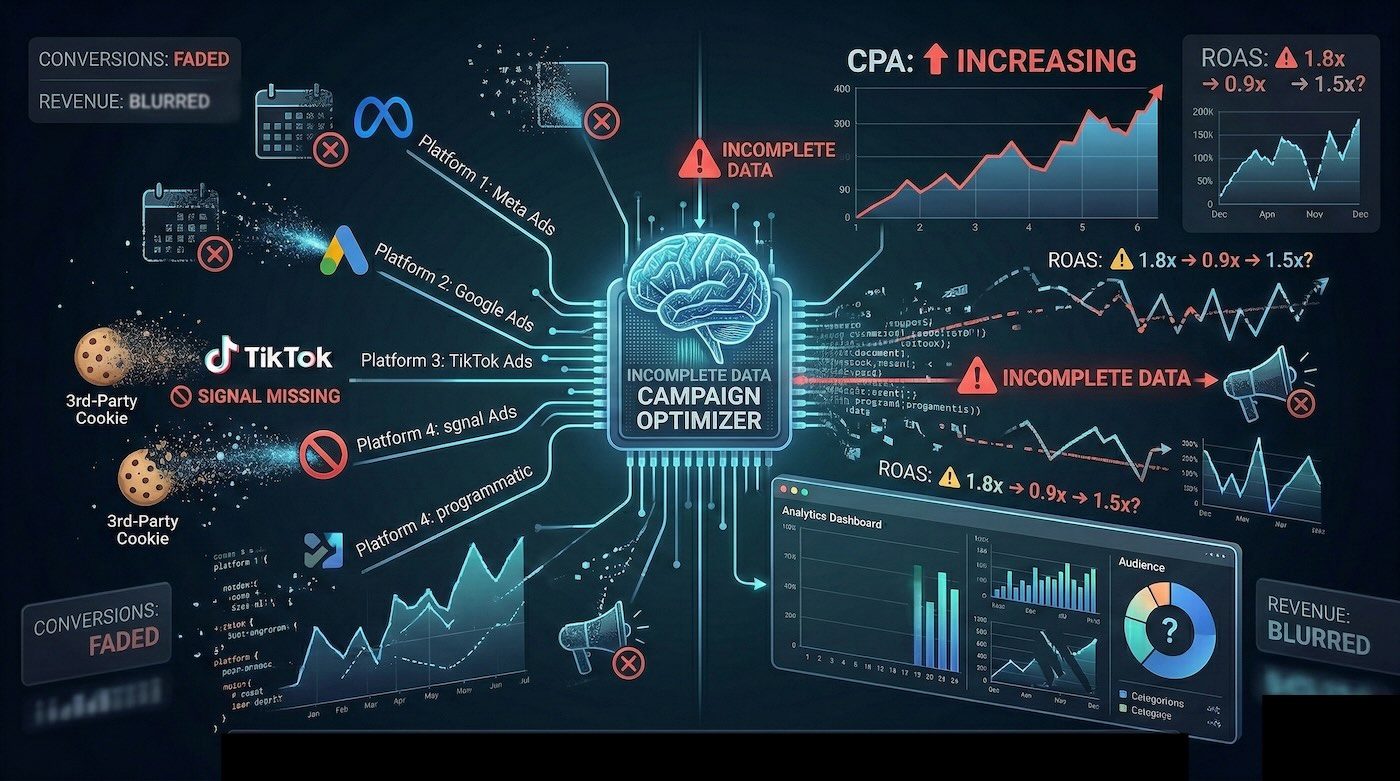
Advertising platforms run on signals. Clicks, events, conversions, consent status, deduplication, and audience quality directly influence how algorithms bid, distribute budget, and decide which users to target.
When a significant share of those signals is lost, the algorithm does not stop working. It continues to operate, but on an incomplete dataset. The result is that automation remains active, but becomes less aligned with actual market behavior.
The operational consequences can be immediate:
- higher CPA due to reduced precision
- lower ROAS due to budget dispersion
- greater performance instability over time
- less effective remarketing segments
- growing difficulty in comparing channels properly
The effect on attribution
Signal loss also alters attribution models. Some channels may appear overestimated, while others may be underestimated. This often leads to budget shifts driven not by real contribution, but by what is more visible in the tracking system.
The real economic impact
The final point is not technical but economic. When measurement weakens, the risk grows of investing in less qualified users, misreading the contribution of channels, and defending apparent KPIs that are only weakly connected to real profit.
That is why server-side tracking makes the most sense when it is embedded in a broader measurement and media strategy, not as an isolated fix, but as part of a structure designed for performance, incrementality, and data quality.
What is server-side tracking?
Server-side tracking consists of sending measurement data from the website’s server, or from an intermediate controlled environment, to analytics and advertising platforms, reducing reliance on the browser as the only point of collection and transmission.
Unlike the client-side model, where JavaScript sends data directly from the browser, in server-side setups the collection and transit of information take place in a more governable environment. This makes it possible to filter, normalize, enrich, or route data before sending it to external platforms.
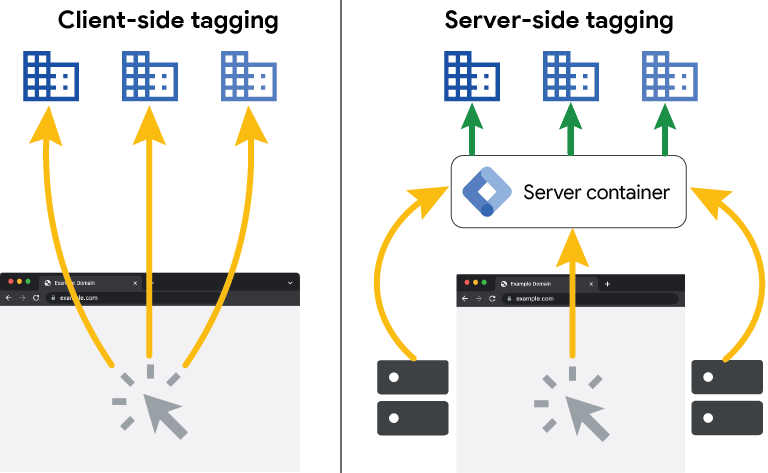
What are the strategic benefits of server-side tracking?
Higher data accuracy
It reduces the impact of browser limitations, ad blockers, and client-side signal loss.
More control and security
Data passes through an environment defined and governed by the business before being sent to third parties.
Stronger governance
It becomes easier to apply filters, transformation rules, pseudonymization, and payload controls.
Technical scalability
It enables advanced integrations with CRM, backend systems, CDPs, data warehouses, and media platforms.
Possible front-end performance improvements
By moving part of the tracking logic out of the browser, pages can become lighter and less complex client-side.
Why is it becoming an increasingly necessary choice?
Server-side tracking is no longer a solution reserved for traditional enterprise environments. It has become relevant even for medium-sized eCommerce businesses and companies that invest continuously in advertising and want to protect the quality of their measurement.
When attribution, audiences, and campaigns directly affect revenue, the gap between observed data and merely estimated data is not a technical detail. It is a business variable.
That is why the real issue today is no longer simply whether to adopt server-side, but how to design a measurement architecture that is coherent with business goals, channels, technology stack, and data governance requirements.
Why this topic requires real measurement expertise
Talking seriously about server-side tracking means understanding not only Google Tag Manager, but also attribution, data quality assurance, Consent Mode, deduplication, media logic, backend integration, and KPI interpretation in a decision-making context.
At HT&T, we approach these projects in an integrated way, connecting tracking, analytics, advertising, and data infrastructure. This is what separates a simple technical setup from a true measurement architecture.
Our experience on data-driven projects is grounded in a structured practice covering Web Analytics, Data Warehouse, performance marketing, and the evolving role of digital visibility, including AI visibility.
In this context, having advanced expertise on Google platforms and measurement systems is not a badge to display, but a concrete responsibility in designing data infrastructures that are more solid, more readable, and more sustainable over time.
Which solutions should be used for server-side tracking?
There is no universal solution. Server-side tracking must be designed according to the technology stack, traffic volume, media pressure, number of involved platforms, and the company’s data maturity.
An eCommerce business running active campaigns across multiple channels, with complex conversion events and deduplication requirements, needs something very different from a corporate website with mainly informational goals. The key variable is not only technical, but strategic: which data is truly critical for the business, and which decisions depend on that data?
The main implementation models
The most common implementations today include environments based on Google Tag Manager Server-Side, dedicated cloud infrastructures, containerized setups, and direct API integrations with platforms such as Google Ads, Meta, and other media ecosystems.
In more advanced contexts, server-side is not simply a technical bridge to advertising platforms. It is an intermediate layer that makes it possible to:
- filter and normalize parameters
- remove or reduce unnecessary sensitive data
- enrich events with backend or CRM data
- manage deduplication and routing across multiple systems
- build a stronger foundation for analysis and activation
Integration with CRM and internal systems
The real value of server-side emerges when it is connected to internal systems such as CRM, ERP, transactional databases, or data warehouses. At that point, tracking stops being only a “marketing issue” and becomes part of a real business measurement infrastructure.
The most common mistake
The most frequent mistake is to treat server-side as a plug-and-play solution. Without coherent design, companies often end up reproducing the same client-side logic in a different environment, without gaining any real strategic advantage.
The difference lies in the design itself: what to measure, how to transform it, where to send it, how to validate it, and how to read it within the broader business framework.
HT&T and Stape: a concrete approach to server-side tracking
When it comes to server-side tracking, the real difference is not made only by the tool that is chosen, but by the way the entire measurement architecture is designed.
At HT&T, we approach these projects starting from business goals, data quality, and consistency across analytics, advertising, consent, and reporting. In this context, Stape can be one of the technological enablers that helps make the deployment of server-side environments faster, more governable, and more scalable, especially in projects based on Google Tag Manager Server-Side.
The platform provides dedicated server-side tagging solutions, GTM server hosting, and features designed for multi-project and multi-client work. This makes it an interesting option when the goal is not simply to activate a container, but to build a stronger data infrastructure for analytics and performance marketing.
Being a Stape partner does not mean offering a shortcut or a standardized setup. For us, it means being able to integrate, where appropriate, a specialized server-side ecosystem into a broader design that includes data governance, attribution, signal quality, and continuity of measurement.
In other words, technology alone is not enough. What matters is a consulting-driven direction capable of translating infrastructure, consent, advertising platforms, and KPIs into a measurement system that is genuinely useful for the business.
Competitive advantage does not come from more invasive tracking, but from a measurement infrastructure that is more governed, more coherent, and more useful to the business.
Further reading in the HT&T perspective
If you are working on digital measurement quality, these related resources can help place server-side tracking within a broader strategic framework:
Conclusions: The winners are not those who track more, but those who govern data better
The digital environment has changed structurally. Privacy-first browsers, consent management, incomplete signals, and the growing role of modeling have turned data quality into a competitive variable.
Continuing to rely only on client-side tracking means accepting an increasing level of opacity in measurement. Server-side tracking does not remove every limitation, does not automatically make a project compliant, and does not replace strategic work. But when designed correctly, it allows a larger share of control to be brought back inside the company’s own infrastructure.
For businesses investing in performance marketing, attribution, audience building, and media optimization, the difference between estimated data and governed data has a direct impact on budget efficiency, stability, and competitiveness.
So today, the right question is not whether to activate server-side “because everyone is doing it,” but which measurement architecture is actually needed for the business, with which goals, which platforms, and which level of data maturity.
Frequently asked questions about server-side tracking
Does server-side tracking completely replace client-side tracking?
No. In most cases, the most effective model is hybrid. Client-side remains useful for part of event collection, while server-side helps govern the most important signals for analytics, advertising, and attribution.
Should server-side tracking and Consent Mode v2 be implemented together?
In most cases, yes. Consent Mode v2 regulates how consent status is communicated to Google, while server-side makes it easier to govern data collection, transformation, and transmission. They solve different problems, but together they create stronger measurement.
Is server-side tracking GDPR compliant?
Not automatically. Server-side does not replace compliance and does not remove the need for correct consent management. It can, however, support stricter governance of data flows, parameter filtering, and pseudonymization before data is sent to third parties.
Does server-side bypass ad blockers?
It can reduce the impact of some browser-side blocks, but it should not be presented as a tool to “bypass the rules.” Its real value lies in improving the governance of the measurement infrastructure, not in promising to recover every lost signal.
How much does server-side improve data quality?
It depends on the industry, architecture, implementation quality, CMP setup, ad blocker pressure, and traffic type. The benefit is not the same for everyone, but in many projects server-side helps rebuild a more coherent and readable data foundation than client-side alone.
Does server-side also improve site performance?
It can help. Moving part of the tracking logic outside the browser can reduce front-end complexity and page weight, but the final result always depends on how the overall project is built.
Do you need Google Tag Manager Server-Side to implement it?
No. Google Tag Manager Server-Side is one of the most common solutions, but it is not the only one. Dedicated cloud architectures, containerized environments, and direct API integrations with advertising platforms can also be used.
Does server-side completely eliminate predictive modeling?
No. Modeling still plays a role in modern analytics and advertising systems. The point is that a well-designed server-side architecture can reduce dependence on exclusively modeled data and increase the share of better-governed signals.
Is server-side suitable for mid-sized eCommerce businesses too?
Yes. It is not a technology reserved for large enterprises. For companies investing continuously in advertising and needing a clearer reading of results, it can become a very concrete lever.
What is the difference between Conversion API and server-side tracking?
Conversion APIs are one of the technical channels that can be used within a server-side architecture. Server-side is the infrastructure model; APIs are one of the ways data is sent to platforms.
Is server-side tracking mandatory today?
No, it is not legally mandatory. But for many businesses investing in performance marketing, it has become strategically important, because client-side tracking alone tends to lose a growing share of signals that are valuable for measurement.
Sources and authoritative references
Google Analytics 4 – Modeling & Consent Mode
Official documentation on predictive models, behavioral modeling, and consent handling in Google Analytics.
Google Tag Manager Server-Side
Technical guide to implementing server-side tagging in a cloud-based infrastructure.
Google Privacy Sandbox
Official updates on the evolution of the privacy-first advertising ecosystem and the context around third-party cookies.
Apple Tracking Prevention Policy
Documentation on tracking limitations introduced by WebKit and Safari.
Meta Conversion API
Official documentation on sending events server-side to Meta.
General Data Protection Regulation (GDPR)
The European legal framework for personal data processing.
IAB Transparency & Consent Framework
European standard for consent handling in digital advertising.
Google Core Web Vitals
Official guidance on web performance and user experience impact.
Stape – Server-Side Tracking and Partner Program
Official pages and documentation on hosting, server-side tagging, and agency partnerships.
Continua a leggere
28 minutes of reading

9 minutes of reading

5 minutes of reading

And it consumes less energy.
To return to the page you were visiting, simply click or scroll.