Server-Side Tracking: cos’è, come funziona e quando serve per analytics e advertising

Cos’è il tracciamento server side e perché è diventato centrale per analytics e advertising
Il tracciamento server side è un’architettura di misurazione digitale in cui i dati vengono raccolti e inviati alle piattaforme di analytics e advertising tramite un server intermedio, anziché direttamente dal browser dell’utente. Parlare oggi di misurazione significa parlare di qualità del dato, governance dei consensi e tenuta delle performance in un ecosistema in cui browser, piattaforme advertising e normative hanno reso fragile il tracciamento tradizionale.
(noto anche come server-side tracking, GTM server side o tracciamento lato server, tutti termini che indicano la stessa architettura di misurazione)
Il server-side tracking non è più un tema per soli addetti ai lavori, ma una scelta architetturale che incide direttamente su attribuzione, campagne media, audience, affidabilità dei report e capacità dell’azienda di prendere decisioni su basi meno frammentate.
Oggi il problema non è la perdita imminente dei cookie di terze parti: Google ha ufficialmente abbandonato quel piano nel 2025, lasciando agli utenti la scelta se disattivarli o meno. Il tema è più strutturale: segnali incompleti, consensi negati, ad-blocker, restrizioni nei browser come Safari e Firefox che bloccano già i cookie di terze parti di default, e una crescente dipendenza da piattaforme che ottimizzano su dati parziali. Il server side tracking resta rilevante non perché “i cookie stanno per morire”, ma perché il browser non è mai stato un ambiente neutro e pienamente controllabile per la misurazione.
Il server-side tracking è particolarmente rilevante anche nelle campagne Meta Ads B2B, dove la qualità del dato incide su attribuzione, ottimizzazione degli eventi e valutazione dei lead generati.
Per questo il server-side va letto non come una scorciatoia tecnica, ma come parte di una strategia più ampia di misurazione privacy-first. In HT&T affrontiamo questo tema in ottica consulenziale, integrando tracking, advertising, web analytics e qualità del dato. È un approccio che portiamo avanti anche grazie a competenze avanzate maturate su ecosistemi di misurazione complessi e supportate dalla nostra esperienza certificata su Google Marketing Platform.
In questo articolo vediamo in modo operativo:
Cos’è il tracciamento client-side?
Il tracciamento client-side si basa sull’esecuzione di script direttamente nel browser dell’utente. Quando il visitatore interagisce con un sito o con un’applicazione, i dati vengono inviati dal browser verso piattaforme di analytics o advertising come Google Analytics, Google Ads, Meta Ads e altri sistemi di misurazione.
Questo modello si fonda prevalentemente su JavaScript, tag di marketing e cookie salvati sul browser, che permettono di riconoscere sessioni, utenti, eventi e conversioni lungo il percorso digitale.
Per anni è stato il modello dominante perché semplice da implementare, veloce da estendere e sufficiente, in molti casi, per leggere il comportamento degli utenti. Ma oggi le condizioni di contesto sono cambiate in modo strutturale.
Limiti del tracciamento client-side in un ecosistema privacy-first e consent-first
Negli ultimi anni l’ecosistema digitale si è spostato verso un modello privacy-first. I browser hanno introdotto protezioni sempre più forti contro forme invasive di tracciamento, mentre piattaforme e normative hanno reso più rigoroso il trattamento dei dati e la gestione del consenso.
Questo significa che il tracciamento client-side è diventato più fragile. Non per la deprecazione dei cookie in Chrome, che non avverrà in modo forzato, ma per ragioni strutturali: Safari e Firefox bloccano già i cookie di terze parti di default coprendo oltre il 30% del traffico globale, gli ad-blocker continuano a crescere, e i consensi negati sulle CMP erodono ulteriormente la base dati osservabile. Il browser non è mai stato, e non sarà, un ambiente neutro e pienamente controllabile per la misurazione.
Le conseguenze ricadono direttamente su:
- attribuzione delle conversioni
- ottimizzazione delle campagne advertising
- analisi dei funnel
- costruzione e attivazione delle audience
- affidabilità dei report a supporto delle decisioni
Quanto incidono i consensi negati sui dati?
L’impatto dei consensi negati può essere molto significativo. I benchmark di mercato mostrano che i tassi di accettazione non sono stabili né omogenei: in molti contesti europei l’opt-in può restare intorno o sotto il 50%, mentre in altri progetti può salire sensibilmente in funzione di brand strength, UX del banner e architettura delle finalità richieste.
Usercentrics, ad esempio, segnala che in alcuni casi un tasso di accettazione attorno al 50% può risultare persino inferiore al benchmark di riferimento, mentre la stessa società evidenzia anche una tendenza più recente: quasi la metà degli utenti dichiara di cliccare accept all meno spesso rispetto a tre anni fa. Questo conferma che l’accettazione del consenso non può essere trattata come una costante acquisita.
In pratica, una parte rilevante del comportamento reale dell’utente può non entrare nella misurazione osservata. E quando analytics e advertising lavorano su una base dati parziale, anche attribuzione, audience e ottimizzazione media diventano meno affidabili.
I numeri della perdita di segnali: quanto dato si perde?
Prima di valutare se e come adottare il tracciamento server side, vale la pena guardare i dati concreti sul fenomeno della perdita di segnali. Le dimensioni del problema sono significative e riguardano tre fronti distinti: ad-blocker, consensi negati e recupero con il server side.
Ad-blocker: una quota strutturale di traffico invisibile
Secondo i dati GWI aggiornati al Q2 2025, almeno il 29,5% degli utenti internet globali utilizza un ad-blocker, per un totale stimato di circa 1,77 miliardi di utenti nel mondo. In Europa la penetrazione è più alta: in media intorno al 40%, con picchi in Germania e Francia dove la propensione al rifiuto dei cookie è già strutturalmente più elevata. Sul desktop, la percentuale sale ulteriormente: secondo alcune stime oltre il 50% degli utenti utilizza forme di blocco lato browser.
Quando un ad-blocker è attivo, il tag Google Analytics non si attiva, il pixel Meta non carica, l’utente acquista e il sistema non registra nulla.
Consensi negati: il problema è peggio di quanto sembra
I dati aggregati da studi 2024-2025 mostrano che il tasso medio di accettazione dei cookie marketing in Europa oscilla tra il 38% e il 47%. Ma la varianza è enorme: banner con pulsante “rifiuta tutto” ugualmente visibile all’accetta registrano tassi di rifiuto dal 50% fino a oltre il 60%. Quando il rifiuto richiede più clic, il dato migliora, ma a costo di violazioni GDPR documentate. Dati Usercentrics indicano che solo il 15% dei banner europei soddisfa i requisiti minimi di compliance.
La tendenza di medio periodo è chiara: nel 2018-2019 la maggioranza degli utenti cliccava “accetta tutto” (60-90%), spesso perché non c’era una vera alternativa visibile. Dal 2021 in poi, con la diffusione delle CMP conformi e la pressione normativa, il rifiuto è diventato la scelta prevalente quando l’opzione è accessibile.
Quanto recupera il server side tracking?
Le implementazioni server side, secondo dati convergenti da più fonti di settore, recuperano in media tra il 20% e il 40% dei dati di attribuzione persi con il solo tracciamento client-side. In termini di conversioni attribuite sulle piattaforme advertising, i benchmark più citati indicano:
- Meta Ads: +10-25% di conversioni attribuite dopo implementazione
server side via Conversion API, con CPA mediamente più basso e migliore efficienza dell’algoritmo Advantage+ - Google Ads: +5-15% di conversioni attribuite, con Smart Bidding che beneficia di segnali più completi nelle prime 2-3 settimane post-implementazione
- Click ID capture rate: in un’implementazione sana dovrebbe superare il 95%; sotto quella soglia l’attribuzione si deteriora in modo rilevante
È importante sottolineare che questi numeri rappresentano segnali recuperati, non revenue aggiuntiva: le conversioni c’erano già, le piattaforme semplicemente non le vedevano. Il dato che cambia è la qualità dell’input agli algoritmi di bidding, con effetti sulla stabilità e sull’efficienza delle campagne.
“Poor cookie consent setup loses 40-60% of advertising measurement data.”
— Secure Privacy, Global Cookie Consent Trends 2026
“Server-side implementations consistently recover 20-40% of attribution data that was previously lost to browser restrictions. When Meta and Google receive more complete conversion signals, their algorithms make smarter bidding decisions.”
— Scribe, Client Side vs Server Side Tracking Compared 2026
Il Machine Learning può compensare la perdita di dati?
Le piattaforme di web analytics e advertising utilizzano sempre di più modelli predittivi per stimare i dati mancanti dovuti a rifiuto dei cookie, ad-blocker o limitazioni dei browser. Ma bisogna essere chiari: si tratta di una compensazione statistica, non di un’osservazione diretta.
Il dato modellato è utile, spesso necessario, ma resta una proiezione probabilistica basata su pattern storici, correlazioni e segnali aggregati. Funziona meglio quando il contesto è stabile. Diventa più fragile quando cambiano canali, messaggi, pubblico, pressione media o qualità dei segnali in ingresso.
Prendiamo come riferimento Google Analytics 4, ma il principio vale anche per altri sistemi evoluti:
Utilizzo dei dati disponibili
I segnali raccolti vengono usati per ricostruire pattern comportamentali e stimare sessioni, utenti e conversioni mancanti.
Modelli predittivi
Algoritmi statistici e di machine learning stimano il dato non osservato sulla base di dati storici e segnali aggregati.
Riempimento dei vuoti informativi
La modellazione prova a colmare la perdita di informazione causata da rifiuti, blocchi o limitazioni lato browser.
Aggiornamento continuo
I modelli vengono ricalibrati nel tempo, ma restano dipendenti dalla qualità e dalla quantità dei segnali di partenza.
Il limite strutturale della modellazione
Il limite non è teorico ma operativo: più aumenta la quota di dato stimato, più aumenta la distanza potenziale tra rappresentazione e realtà. E quando a essere modellati sono segnali usati per attribuzione, bidding o remarketing, l’impatto si propaga lungo tutto il sistema marketing.
- attribuzione cross-channel meno stabile
- valore reale delle conversioni meno leggibile
- audience meno precise
- ottimizzazioni media più dipendenti da pattern incompleti
Il problema quindi non è la modellazione è sbagliata. Il punto è un altro: se il business ottimizza su una base dati troppo parziale, la qualità della decisione si indebolisce.
Il punto non è raccogliere più dati possibile, ma ridurre la distanza tra dato osservato, dato modellato e decisione di business.
Anche per questo oggi ha senso collegare il tema del server-side non solo al tracking, ma a una visione più ampia della misurazione e dell’allocazione del budget, come approfondiamo anche nell’articolo su ROAS, AI e profitto reale.
Avere più dati governati non basta se poi non sono leggibili in modo rapido.
Su questo tema è utile la guida alla data visualization per semplificare i dati e velocizzare le decisioni, perché il vantaggio del server-side si realizza solo quando il dato arriva pulito a chi deve usarlo.
Server-side tracking e Consent Mode v2: non sono la stessa cosa
Uno degli errori più frequenti è confondere server-side tracking e Consent Mode v2. In realtà risolvono problemi diversi e lavorano su livelli differenti.
Il Consent Mode v2 serve a comunicare alle piattaforme Google lo stato dei consensi dell’utente e a regolare il comportamento dei tag in base a quella scelta. Il server-side tracking, invece, è un’architettura di raccolta, trasformazione e instradamento del dato in un ambiente controllato dal business.
In pratica: il Consent Mode governa la relazione tra consenso e attivazione dei tag; il server-side governa la qualità del passaggio tecnico dei dati, il filtraggio dei parametri, l’arricchimento con dati interni, la deduplica e l’invio verso più piattaforme.
Separati, hanno utilità diverse. Insieme, possono contribuire a una misurazione più robusta, coerente e meno dipendente dal solo browser.
Impatto diretto sulle campagne pubblicitarie
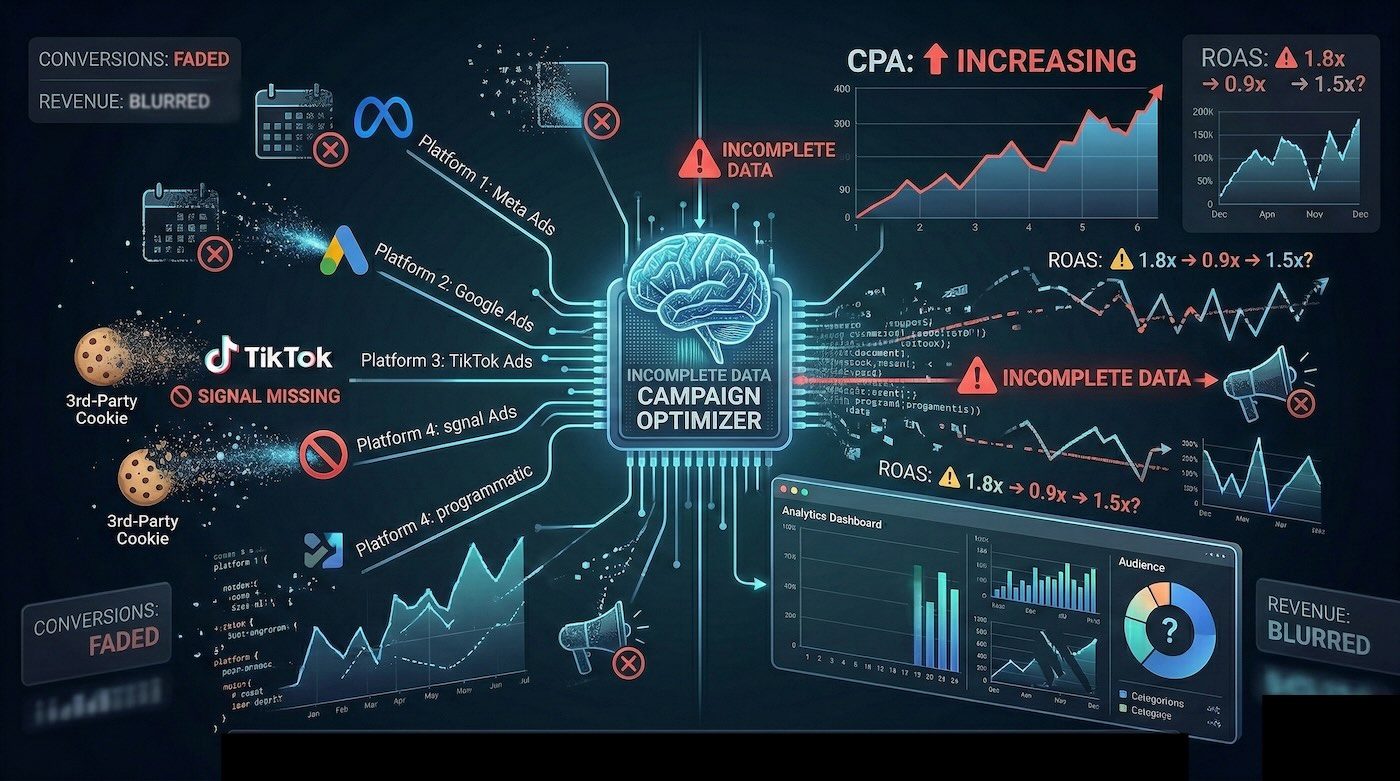
Le piattaforme advertising funzionano su segnali. Click, eventi, conversioni, consenso, deduplica e qualità delle audience influenzano direttamente il modo in cui gli algoritmi fanno bidding, distribuiscono budget e selezionano gli utenti da raggiungere.
Quando una quota rilevante di questi segnali viene persa, l’algoritmo non smette di lavorare. Continua a farlo, ma su un dataset incompleto. Il risultato è che l’ottimizzazione automatica rimane attiva, ma diventa meno aderente al comportamento reale del mercato.
Le conseguenze operative possono essere immediate:
- aumento del CPA per perdita di precisione
- riduzione del ROAS per dispersione del budget
- maggiore instabilità delle performance nel tempo
- segmenti di remarketing meno efficaci
- difficoltà crescente nel confrontare canali in modo corretto
Per capire come questi segnali incompleti impattano concretamente sulle campagne, è utile leggere la guida a Google Ads per ecommerce e Performance Max: Smart Bidding e Performance Max dipendono direttamente dalla qualità dei segnali di conversione che ricevono.
L’effetto sull’attribuzione
La perdita di segnali altera anche i modelli di attribuzione. Alcuni canali possono risultare sovrastimati, altri sottostimati. Questo porta spesso a spostare budget non sulla base del contributo reale, ma sulla base di ciò che è più visibile nel sistema di tracking.
L’impatto economico reale
Il punto finale è economico. Quando la misurazione si indebolisce, aumenta il rischio di investire su utenti meno qualificati, leggere male il contributo dei canali e difendere KPI apparenti ma poco collegati al profitto reale.
Per questo il server-side tracking ha senso soprattutto quando viene inserito dentro una strategia più ampia di misurazione e media, non come fix isolato ma come tassello di una struttura orientata a performance, incrementalità e qualità del dato.
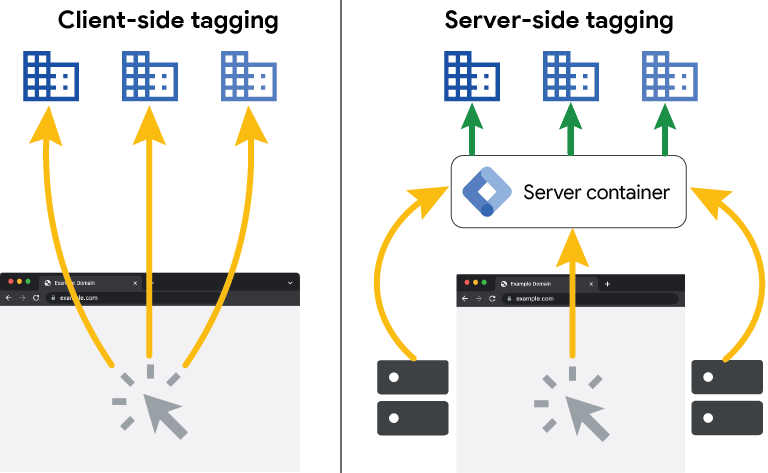
Come funziona il tracciamento server side: architettura e differenze col client-side
Il tracciamento server-side consiste nell’inviare i dati di misurazione dal server del sito o da un ambiente intermedio controllato verso le piattaforme di analytics e advertising, riducendo la dipendenza dal browser come unico punto di raccolta e invio dei segnali.
A differenza del modello client-side, in cui gli script JavaScript inviano i dati direttamente dal browser, nel server-side la raccolta e il passaggio delle informazioni avvengono in un ambiente più governabile. Questo permette di filtrare, normalizzare, arricchire o instradare i dati prima dell’invio alle piattaforme esterne.
In pratica: quando un utente completa un acquisto, invece di inviare l’evento di conversione solo tramite il pixel nel browser (che può essere bloccato o perso), il server del sito invia lo stesso evento direttamente alle piattaforme come Google Ads o Meta tramite le loro API. Il browser rimane il punto di partenza dell’interazione, ma non è più l’unico canale di trasmissione del dato.
Quali sono i vantaggi strategici del server-side tracking?
Maggiore precisione del dato
Riduce l’impatto di limitazioni browser, ad-blocker e perdita di segnali lato client.
Controllo e sicurezza
I dati passano attraverso un ambiente definito e governato dal business prima di essere inviati verso terze parti.
Governance più strutturata
È più semplice applicare filtri, regole di trasformazione, pseudonimizzazione e controlli sui payload.
Scalabilità tecnica
Consente integrazioni avanzate con CRM, backend, CDP, data warehouse e piattaforme media.
Possibile miglioramento delle performance front-end
Spostando una parte della logica fuori dal browser, si può alleggerire la pagina e ridurre complessità lato client.
Data stream consolidation
Il server SGTM può fungere da hub unico: si invia un singolo stream di dati dal sito al server, e dal server lo si distribuisce in parallelo a GA4, Meta CAPI, Google Ads, TikTok e altri sistemi.
Questo riduce drasticamente il codice JavaScript in pagina con impatto diretto sui Core Web Vitals.
Arricchimento dati con segnali CRM
Sul server è possibile arricchire gli eventi con dati interni (margini di profitto, qualifica del lead, valore cliente) senza mai esporli nel browser. È questo il caso d’uso che oggi ha reso il server side tracking rilevante non solo per il marketing, ma per l’intera infrastruttura dati aziendale.
Perché oggi è una scelta sempre più necessaria?
Il server-side tracking non è più una soluzione da enterprise nel senso tradizionale del termine. È diventato rilevante anche per eCommerce e aziende di medie dimensioni che investono in advertising in modo continuativo e vogliono proteggere la qualità della propria misurazione.
Quando attribution, audience e campagne incidono direttamente sui ricavi, la differenza tra dato osservato e dato solo stimato non è un dettaglio tecnico. È una variabile di business.
Per questo oggi il tema non è più soltanto se adottare il server-side, ma come progettare una misurazione coerente con obiettivi, canali, stack tecnologico e governance dei dati aziendali.
Perché questo tema richiede competenze reali di misurazione
Parlare seriamente di server-side tracking significa conoscere non solo Google Tag Manager, ma anche attribuzione, quality assurance del dato, Consent Mode, deduplica, logiche media, integrazione con backend e lettura dei KPI in chiave decisionale.
In HT&T affrontiamo questi progetti in modo integrato, collegando tracking, analytics, advertising e infrastruttura dati. È questo il passaggio che distingue un semplice setup tecnico da una vera architettura di misurazione.
La nostra esperienza su progetti data-driven si appoggia a una pratica strutturata di Web Analytics, Data Warehouse, performance marketing e lettura dell’evoluzione del digitale anche lato AI visibility.
In questo scenario, essere tra le agenzie con competenze avanzate sulle piattaforme Google e sui sistemi di misurazione non è un badge da esibire, ma una responsabilità concreta nel progettare infrastrutture dati più solide, leggibili e sostenibili nel tempo.
Quali soluzioni utilizzare per il server-side tracking?
Non esiste una soluzione universale. L’implementazione del server-side tracking deve essere progettata in base allo stack tecnologico, al volume di traffico, alla pressione media, al numero di piattaforme coinvolte e alla maturità dei dati in azienda.
Un eCommerce con campagne attive su più canali, eventi di conversione complessi e necessità di deduplica ha esigenze diverse rispetto a un sito corporate con finalità informative. La variabile chiave dunque non è solo tecnica, ma strategica: quali dati sono davvero critici per il business e quali decisioni dipendono da quei dati?
I principali modelli di implementazione
Le implementazioni più diffuse oggi includono ambienti basati su Google Tag Manager
Server-Side (SGTM), infrastrutture cloud dedicate, setup containerizzati e integrazioni
dirette via API verso piattaforme come Google Ads, Meta, TikTok e LinkedIn. Da aprile 2025 GTM
ha introdotto il caricamento automatico del Google Tag nei container con tag Google Ads e Floodlight,
un aggiornamento che impatta direttamente la gestione delle Enhanced Conversions e dei dati forniti
dagli utenti (User-Provided Data). Chi gestisce implementazioni GTM deve verificare che questa
modifica non abbia alterato la propria configurazione, specialmente in presenza di Consent Mode.
Nei contesti più evoluti, il server-side non è un semplice ponte tecnico verso le piattaforme advertising, ma un layer intermedio che permette di:
- filtrare e normalizzare i parametri
- rimuovere o ridurre dati sensibili non necessari
- arricchire gli eventi con dati backend o CRM
- gestire meglio deduplica e instradamento verso più sistemi
- creare una base più robusta per analisi e attivazione
Per chi gestisce un ecommerce su Shopify, vale la pena leggere anche la guida al Shopify Custom Pixel, che rappresenta il punto di partenza lato client prima di costruire un’architettura server-side completa.
Integrazione con CRM e sistemi interni
Il vero valore del server-side emerge quando viene collegato a sistemi interni come CRM, ERP, database transazionali o data warehouse. In quel momento il tracking smette di essere soltanto un tema “marketing” e diventa parte di una vera infrastruttura di misurazione del business.
L’errore più comune
L’errore più frequente è trattare il server-side come una soluzione plug-and-play. Senza una progettazione coerente, si finisce per replicare le stesse logiche client-side in un ambiente diverso, senza ottenere un vero vantaggio strategico.
La differenza la fa la progettazione: cosa misurare, come trasformarlo, dove inviarlo, come validarlo e come leggerlo dentro il framework complessivo del business.
Google Tag Manager Server-Side (sGTM): come funziona e perché è la soluzione più adottata
Google Tag Manager Server-Side — comunemente chiamato sGTM — è l’implementazione più diffusa di server-side tracking nel mercato italiano ed europeo. Non è l’unica soluzione disponibile, ma è quella che combina il maggiore ecosistema di tag pre-costruiti, l’integrazione nativa con Google Analytics 4 e Google Ads, e la curva di apprendimento più accessibile per chi già usa GTM client-side.
L’architettura di base prevede tre componenti: un container client (il GTM tradizionale nel browser), un container server (ospitato su cloud) e le piattaforme di destinazione — GA4, Google Ads, Meta CAPI, TikTok Events API e altri. Il browser invia un singolo stream di dati al container server, che li trasforma e li redistribuisce in parallelo verso tutte le destinazioni configurate.
GTM client-side vs GTM server-side: le differenze operative
| Aspetto | GTM client-side | GTM server-side (sGTM) |
|---|---|---|
| Dove gira | Browser dell’utente | Server cloud (GCP, AWS, Stape…) |
| Impatto ad-blocker | Alto — molti tag vengono bloccati | Ridotto — i dati partono dal server |
| Performance front-end | Peggiora all’aumentare dei tag | Migliora — meno script in pagina |
| Controllo sui dati | Limitato — dati visibili nel browser | Alto — filtraggio e trasformazione lato server |
| Arricchimento con dati CRM | Non possibile in modo sicuro | Possibile — i dati non passano dal browser |
| Complessità implementativa | Bassa — configurazione guidata | Media-alta — richiede infrastruttura cloud |
| Costo | Gratuito | Costo infrastruttura cloud (~50–200€/mese per progetti standard) |
Il nuovo comportamento automatico del Google Tag
Da aprile 2025, GTM ha introdotto il caricamento automatico del Google Tag nei container che includono tag Google Ads o Floodlight. Questo aggiornamento impatta direttamente la gestione delle Enhanced Conversions e dei User-Provided Data (UPD). Chi gestisce implementazioni GTM deve verificare che questa modifica non abbia alterato la propria configurazione — specialmente in presenza di Consent Mode v2, dove un Google Tag caricato in modo duplicato può alterare la trasmissione degli stati di consenso.
La verifica si fa controllando: (1) se il Google Tag appare duplicato nel debug di GTM, (2) se gli eventi Enhanced Conversions riportano dati coerenti nel pannello Google Ads, (3) se il Consent Mode riporta gli stati corretti nel tag di diagnostica.
First party data e server-side tracking: il collegamento strategico
Il termine first party data indica i dati raccolti direttamente dall’azienda attraverso le proprie interazioni con utenti e clienti — acquisti, iscrizioni, comportamenti sul sito, dati CRM, storico ordini. A differenza dei dati di terze parti (cookie third-party, audience di piattaforme esterne), i first party data sono di proprietà dell’azienda e non dipendono da accordi con intermediari.
Il legame con il server-side tracking è diretto: il server è l’unico ambiente in cui i first party data possono essere arricchiti, combinati e utilizzati in modo sicuro prima dell’invio alle piattaforme advertising. Nel browser questo non è possibile — qualsiasi dato presente lato client è accessibile a script di terze parti e visibile nelle DevTools.
Quando i first party data vengono centralizzati in modo strutturato, il passo successivo è spesso l’integrazione con un sistema di storage dedicato: la guida al Data Warehouse per PMI mostra come costruire una base dati unificata che alimenta sia analytics che advertising.
Come il server-side attiva i first party data nelle campagne
- Enhanced Conversions Google Ads — invio di dati forniti dall’utente (email, telefono, indirizzo) in formato hashato per migliorare l’attribuzione delle conversioni
- Meta Conversion API con Customer Information Parameters — arricchimento degli eventi con dati CRM per aumentare il match rate e ridurre il costo per conversione
- Audience building da dati interni — utilizzo di segmenti CRM per costruire audience su piattaforme advertising senza dipendere da cookie third-party
- Profit-based bidding — invio del margine reale per ordine invece del solo revenue, per ottimizzare le campagne sul profitto effettivo anziché sul fatturato
- Lead scoring su advertising — trasmissione della qualifica del lead dal CRM alle piattaforme per ottimizzare su lead qualificati, non su tutti i form compilati
Strumenti per implementare il tracciamento server side: il caso Stape
Tra gli strumenti più utilizzati per implementare il tracciamento server side su Google Tag Manager c’è Stape, una piattaforma specializzata in hosting e gestione di container server-side. Offre soluzioni dedicate al server-side tagging, infrastruttura cloud ottimizzata per GTM Server-Side e funzionalità pensate per la gestione multi-progetto.
È particolarmente utile nei contesti in cui il setup deve essere rapido, governabile e scalabile senza dover gestire internamente l’infrastruttura cloud. Non è l’unica opzione disponibile (esistono implementazioni su Google Cloud, AWS o Azure), ma è tra le più adottate in ambito agenzia per la sua semplicità operativa.
La scelta dello strumento, in ogni caso, viene dopo la progettazione: cosa misurare, come trasformarlo, dove inviarlo e come validarlo rispetto agli obiettivi di business.
Oggi il vantaggio competitivo non nasce da un tracking più invasivo, ma da un’infrastruttura di misurazione più governata, coerente e utile al business.
Per approfondire il tema in ottica HT&T
Se stai lavorando sulla qualità della misurazione digitale, questi approfondimenti possono aiutarti a contestualizzare meglio il ruolo del server-side tracking dentro una strategia più ampia:
Conclusioni: nei tempi odierni vince chi governa meglio il dato il modo corretto.
Il contesto digitale è cambiato in modo strutturale. Browser privacy-first, gestione dei consensi, segnali incompleti e crescente peso della modellazione hanno trasformato la qualità del dato in una variabile competitiva.
Continuare a basarsi solo su un tracciamento client-side significa accettare una quota crescente di opacità nella misurazione. Il server-side tracking non elimina ogni limite, non rende automaticamente compliant un progetto e non sostituisce il lavoro strategico. Ma, se progettato correttamente, consente di riportare una quota maggiore di controllo all’interno dell’infrastruttura aziendale.
Per chi investe in performance marketing, attribuzione, audience e ottimizzazione media, la differenza tra dato stimato e dato governato ha un impatto diretto su budget, stabilità e competitività.
Oggi, quindi, la domanda giusta non è se attivare il server-side perché è di moda, ma quale architettura di misurazione serve davvero al proprio business, con quali obiettivi, quali piattaforme e quale livello di maturità del dato.
Domande frequenti sul tracciamento server-side
Il server-side tracking sostituisce completamente il tracciamento client-side?
No. Nella maggior parte dei casi il modello più efficace è ibrido. Il client-side continua a essere utile per una parte della raccolta eventi, mentre il server-side aiuta a governare meglio i segnali più importanti per analytics, advertising e attribuzione.
Server-side tracking e Consent Mode v2 vanno implementati insieme?
Nella maggior parte dei casi sì. Il Consent Mode v2 regola la comunicazione dello stato dei consensi verso Google, mentre il server-side consente di governare meglio raccolta, trasformazione e invio dei dati. Risolvono problemi diversi, ma insieme costruiscono una misurazione più solida.
Il server-side tracking è conforme al GDPR?
Non automaticamente. Il server-side non sostituisce la compliance e non elimina la necessità di una corretta gestione del consenso. Può però facilitare una governance più rigorosa dei flussi di dati, del filtraggio dei parametri e della pseudonimizzazione prima dell’invio a terze parti.
Il server-side aggira gli ad-blocker?
Riduce l’impatto di alcuni blocchi lato browser, ma non va presentato come uno strumento per “aggirare le regole”. Il suo valore reale sta nel migliorare il governo dell’infrastruttura di misurazione, non nel promettere il recupero totale di ogni dato perso.
Quanto migliora la qualità del dato con il server-side?
Dipende da settore, architettura, qualità dell’implementazione, CMP, pressione degli ad-blocker e tipo di traffico. Il beneficio reale non è uguale per tutti, ma in molti progetti il server-side aiuta a ricostruire una base dati più coerente e leggibile rispetto al solo tracciamento client-side.
Il server-side migliora anche le performance del sito?
Può contribuire a farlo. Spostare una parte della logica di tracking fuori dal browser può alleggerire la pagina e ridurre complessità front-end, ma il risultato dipende sempre da come il progetto è costruito nel complesso.
Serve Google Tag Manager Server-Side per implementarlo?
No. Google Tag Manager Server-Side è una delle soluzioni più diffuse, ma non è l’unica. Si possono usare anche architetture cloud dedicate, ambienti containerizzati o integrazioni API verso le piattaforme advertising.
Il server-side elimina completamente la modellazione predittiva?
No. La modellazione continua ad avere un ruolo nei sistemi moderni di analytics e advertising. Il punto è che una buona architettura server-side può ridurre la dipendenza da dati esclusivamente modellati e aumentare la quota di segnali meglio governati.
Il server-side è adatto anche a eCommerce di medie dimensioni?
Sì. Non è una tecnologia riservata alle grandi enterprise. Per aziende che investono in advertising in modo continuativo e hanno bisogno di leggere meglio i risultati, può diventare una leva molto concreta.
Qual è la differenza tra Conversion API e server-side tracking?
Le Conversion API sono uno dei canali tecnici utilizzabili dentro un’architettura server-side. Il server-side è il modello infrastrutturale; le API sono uno dei modi attraverso cui i dati vengono inviati alle piattaforme.
Il server-side tracking è obbligatorio?
No, non è obbligatorio per legge. Ma per molte aziende che fanno performance marketing è diventato strategicamente rilevante, perché il solo tracking client-side tende a perdere una quota crescente di segnali utili alla misurazione.
Fonti e riferimenti autorevoli
Google Analytics 4 – Modeling & Consent Mode
Documentazione ufficiale sui modelli predittivi, sul behavioral modeling e sulla gestione del consenso in Google Analytics.
Google Tag Manager Server-Side
Guida tecnica all’implementazione del tagging server-side su infrastruttura cloud.
Google Privacy Sandbox
Aggiornamenti ufficiali sull’evoluzione dell’ecosistema advertising privacy-first e sul contesto dei cookie di terze parti.
Apple Tracking Prevention Policy
Documentazione sulle limitazioni introdotte da WebKit e Safari rispetto al tracciamento.
Meta Conversion API
Documentazione ufficiale sull’invio server-side di eventi verso Meta.
Regolamento Generale sulla Protezione dei Dati (GDPR)
Quadro normativo europeo sul trattamento dei dati personali.
IAB Transparency & Consent Framework
Standard europeo per la gestione dei consensi nel digital advertising.
Google Core Web Vitals
Linee guida ufficiali sulle performance web e sull’impatto dell’esperienza utente.
Stape – Server-Side Tracking e Partner Program
Documentazione e pagine ufficiali relative a hosting, server-side tagging e partnership per agenzie.
Continua a leggere
23 minuti di lettura

28 minuti di lettura

E fa consumare meno energia.
Per tornare alla pagina che stavi visitando ti basterà cliccare o scorrere.