L’Importanza del tracciamento Server-Side nell’analisi dei dati online

Importanza del tracciamento server-side nell’analisi dei dati online
Nell’attuale ecosistema digitale, caratterizzato da restrizioni sui cookie, browser privacy-first e crescente sensibilità normativa,
il tracciamento server-side rappresenta una delle evoluzioni più strategiche per garantire continuità, qualità e affidabilità del dato.
Le aziende che basano le proprie decisioni su performance marketing, attribution modeling e analisi predittiva non possono più dipendere esclusivamente dal tracciamento client-side.
La perdita di segnali, l’adozione diffusa di ad-blocker e l’inasprimento delle policy dei browser rendono necessario un approccio più solido e controllabile.
In questo articolo analizziamo in modo operativo:
- Cos’è il tracciamento client-side
- I suoi limiti nel contesto cookieless
- L’impatto dei rifiuti cookie sui dati
- Perché il server-side tracking è oggi una scelta strategica
Cos’è il tracciamento client-side?
Il tracciamento client-side si basa sull’esecuzione di script direttamente nel browser dell’utente.
Quando un visitatore interagisce con un sito o un’applicazione, i dati vengono inviati in modo diretto verso piattaforme di analisi o advertising come Google Analytics, Google Ads, Meta Ads o altri sistemi di misurazione.
Questo modello si fonda prevalentemente sull’utilizzo dei cookie, file testuali memorizzati nel browser che consentono l’identificazione e la misurazione del comportamento dell’utente nel tempo.
Limiti del tracciamento client-side nel contesto cookieless
Negli ultimi anni l’ecosistema digitale si è orientato verso un modello privacy-centric.
I principali browser hanno introdotto sistemi di protezione avanzata che limitano fortemente la durata e l’utilizzo dei cookie.
Tecnologie come l’Intelligent Tracking Prevention (ITP) riducono la capacità di tracciare gli utenti, bloccano i cookie di terze parti e limitano la durata dei cookie di prima parte.
Inoltre, vengono contrastate tecniche alternative come il fingerprinting.
Parallelamente, l’evoluzione della Privacy Sandbox di Google ha ridefinito il modo in cui i dati pubblicitari possono essere utilizzati e condivisi, introducendo modelli basati su aggregazione e segnali anonimizzati.
Il risultato è una progressiva perdita di precisione nei dati raccolti via browser, con impatti diretti su:
- Attribuzione delle conversioni
- Ottimizzazione delle campagne advertising
- Analisi dei funnel
- Modelli di remarketing
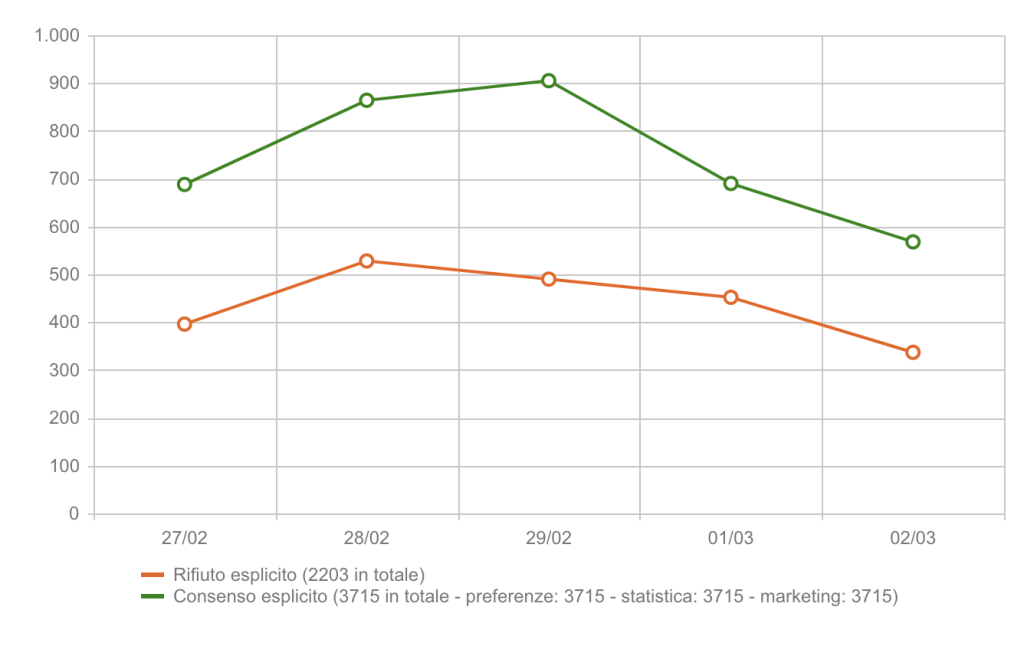
Quanto incidono i consensi negati sui dati?
Analizzando diversi settori merceologici attraverso piattaforme CMP, il rifiuto al consenso
varia mediamente tra il 30% e il 60% dei dati potenzialmente tracciabili.
Una corretta configurazione della CMP e una classificazione granulare dei cookie
consentono di mantenersi nella fascia bassa (30–40%).
In assenza di ottimizzazione tecnica e legale, è frequente superare il 55–60% di perdita.
Questo significa che una parte significativa del traffico reale non viene registrata
dalle piattaforme di analytics e advertising.
Il Machine Learning può compensare la perdita di dati?
Le piattaforme di web analytics moderne utilizzano modelli predittivi per stimare i dati mancanti dovuti a rifiuto dei cookie, ad-blocker o limitazioni dei browser.
Tuttavia, si tratta sempre di una compensazione statistica, non di una misurazione osservata.
Il dato modellato è una proiezione probabilistica basata su pattern storici.
Funziona finché il contesto rimane stabile. Ma quando cambiano comportamenti, canali o mix di traffico, la distanza tra dato reale e dato stimato può aumentare rapidamente.
Prendiamo come riferimento Google Analytics 4 (GA4), ma il principio è analogo per qualsiasi sistema di analytics evoluto o piattaforma advertising.
Utilizzo dei dati disponibili
I segnali raccolti vengono utilizzati per identificare pattern comportamentali e stimare volumi di traffico e conversioni.
Modelli predittivi
Algoritmi di machine learning stimano sessioni e conversioni sulla base di dati storici, correlazioni statistiche e segnali aggregati.
Riempimento dei dati mancanti
Tecniche di interpolazione e modellazione colmano i vuoti informativi generati da consensi negati o restrizioni browser.
Aggiornamento continuo dei modelli
I modelli vengono ricalibrati in base ai nuovi dati osservati per mantenere coerenza statistica.
Il limite strutturale della modellazione
La modellazione funziona in modo relativamente affidabile quando la perdita dati rimane contenuta (35–40%). Superata una certa soglia, l’incertezza statistica aumenta in modo esponenziale.
Non è solo una questione di “numero di sessioni”.
La perdita impatta soprattutto:
- Attribuzione cross-channel
- Valore reale delle conversioni
- Costruzione di audience lookalike
- Ottimizzazione automatica delle campagne
Quando il sistema ottimizza su dati stimati, l’intero processo decisionale diventa meno ancorato alla realtà operativa.
Il problema quindi non è solo analitico ma anche strategico.
Se il dato è parzialmente osservato e parzialmente modellato, anche le decisioni di budget e allocazione media si basano su una rappresentazione incompleta.
Il server-side tracking non elimina la modellazione, ma riduce la dipendenza da essa, riportando una quota maggiore di dati nell’ambito dell’osservazione diretta.
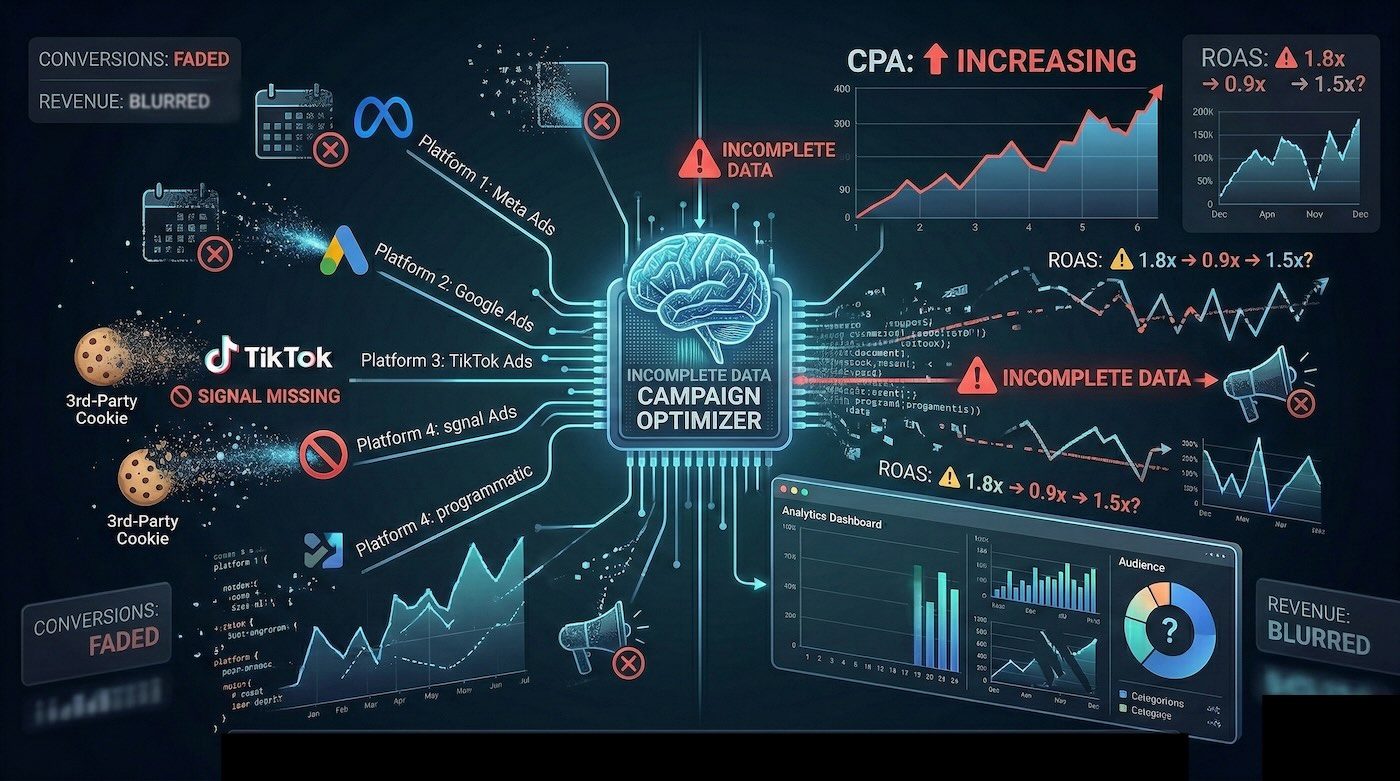
Impatto diretto sulle campagne pubblicitarie
Le piattaforme advertising funzionano su segnali.
Ogni click, evento e conversione alimenta l’algoritmo di ottimizzazione.
Quando una quota rilevante di questi segnali viene persa, l’algoritmo continua a lavorare, ma su un dataset incompleto.
Se il sistema non dispone di dati completi, la costruzione delle audience diventa meno accurata e le logiche di bidding automatico si basano su una rappresentazione parziale del comportamento reale.
Le conseguenze operative sono immediate:
- Aumento del CPA per perdita di precisione nell’ottimizzazione
- Riduzione del ROAS per dispersione del budget
- Maggiore instabilità delle performance nel tempo
- Minor efficacia dei segmenti di remarketing
L’effetto sull’attribuzione
La perdita di segnali altera anche i modelli di attribuzione.
Canali apparentemente meno performanti possono risultare sovrastimati o sottostimati, portando a decisioni di riallocazione budget non coerenti con la realtà.
In presenza di una perdita dati del 40–50%, l’ottimizzazione automatica rischia di inseguire pattern incompleti, con un effetto cumulativo nel tempo: meno dati osservati → meno precisione → maggior costo per conversione.
L’impatto economico reale
Non si tratta solo di una questione tecnica.
Ogni punto percentuale di inefficienza nell’algoritmo si traduce in budget investito su utenti meno qualificati.
In altre parole: si investe su pubblici meno precisi, si alza il costo di acquisizione e si riduce la marginalità.
Ridurre la perdita di segnali attraverso un’infrastruttura server-side significa fornire agli algoritmi dati più completi, migliorando stabilità, scalabilità e sostenibilità delle campagne nel medio periodo.
Cos’è il tracciamento server-side?
Il tracciamento server-side consiste nell’inviare i dati di misurazione dal server del sito verso le piattaforme di analytics o advertising, senza dipendere direttamente dal browser dell’utente.
A differenza del modello client-side, in cui lo script JavaScript invia i dati dal browser,
nel server-side la raccolta e l’elaborazione avvengono in un ambiente controllato.
Quali sono i vantaggi strategici del server-side tracking?
Maggiore precisione del dato
Riduce l’impatto di ad-blocker, limitazioni browser e restrizioni sui cookie.
Controllo e sicurezza
I dati transitano attraverso un ambiente proprietario prima di essere inviati alle piattaforme esterne.
Gestione più efficace dei consensi
Permette una governance più strutturata in ottica GDPR e compliance.
Scalabilità tecnica
Consente integrazioni avanzate con CRM, CDP, sistemi backend e data warehouse.
Ottimizzazione delle performance
Riduce il carico di script lato browser e migliora i tempi di caricamento.
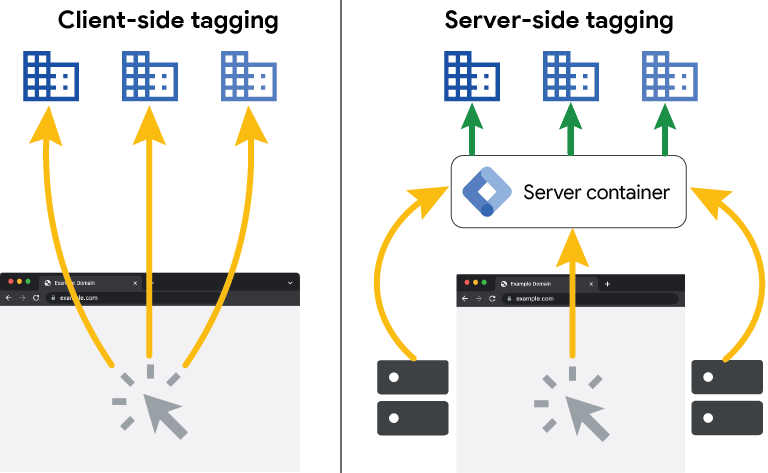
Perché oggi è una scelta necessaria?
Il server-side tracking non è più una soluzione opzionale per grandi enterprise.
È una scelta strategica per qualsiasi azienda che investa in performance marketing.
Permette di ricostruire una base dati più solida, migliorare l’attribuzione, ottimizzare le campagne e ridurre la dispersione del budget.
Competenza certificata Google Marketing Platform
La certificazione Google Marketing Platform attesta competenze avanzate nell’implementazione di Google Analytics, Google Tag Manager e infrastrutture di misurazione complesse.
In Italia solo poche agenzie possiedono questa certificazione.
È un riconoscimento concreto della capacità di progettare architetture di tracking coerenti, scalabili e orientate alla qualità del dato.
Quali soluzioni utilizzare per il server-side tracking?
Non esiste una soluzione universale.
L’implementazione del server-side tracking deve essere progettata in base allo stack tecnologico, al volume di traffico, al livello di investimento advertising e alla maturità dell’infrastruttura dati aziendale.
Un eCommerce con campagne performance attive su più piattaforme richiede un’architettura diversa rispetto a un sito corporate con finalità prevalentemente informative.
La variabile chiave non è solo tecnica, ma strategica: quali dati sono realmente critici per il business?
I principali modelli di implementazione
Le implementazioni più diffuse oggi includono ambienti server-side basati su Google Tag Manager Server-Side, infrastrutture cloud proprietarie (ad esempio su ambienti containerizzati) oppure integrazioni dirette tramite API verso piattaforme advertising come Google Ads o Meta.
Nei contesti più evoluti, il server-side non è un semplice “ponte” verso le piattaforme media, ma un layer intermedio che consente:
- Filtraggio e normalizzazione dei parametri
- Anonimizzazione e controllo dei dati sensibili
- Arricchimento con dati CRM o backend
- Instradamento differenziato verso più piattaforme
Integrazione con CRM e sistemi interni
Il vero valore del server-side emerge quando viene integrato con sistemi interni come CRM, ERP o data warehouse.
Questo consente di collegare il comportamento digitale con informazioni di business reali, migliorando la qualità delle audience e la precisione dell’attribuzione.
In questo scenario, il server-side diventa parte di un’infrastruttura dati più ampia e strutturata, non un semplice intervento tecnico isolato.
L’errore più comune
L’errore più frequente è trattare il server-side come un’attivazione plug-and-play.
Senza una progettazione architetturale coerente, si rischia di replicare semplicemente le logiche client-side, senza reale beneficio strategico.
Una corretta progettazione fa la differenza tra un semplice setup tecnico e un’infrastruttura dati realmente performante, scalabile e sostenibile nel tempo.
Conclusioni: dal dato stimato al dato governato
Il contesto digitale è cambiato in modo strutturale.
Browser privacy-first, limitazioni ai cookie e aumento dei consensi negati hanno trasformato la qualità del dato in una variabile critica.
Continuare a basarsi esclusivamente su un tracciamento client-side significa accettare una perdita sistemica di informazioni e delegare la misurazione a modelli predittivi sempre più invasivi.
Il server-side tracking non è una scorciatoia tecnica.
È una scelta architetturale che consente di riportare il controllo del dato all’interno dell’infrastruttura aziendale.
Per le aziende che investono in performance marketing, attribuzione avanzata e costruzione di audience qualificate, la differenza tra dato stimato e dato governato si traduce direttamente in efficienza del budget e competitività.
Oggi il tema non è più se adottare un’infrastruttura server-side, ma come progettarla in modo coerente con gli obiettivi di business.
Domande frequenti sul tracciamento server-side
Il server-side tracking sostituisce completamente il tracciamento client-side?
No. Nella maggior parte dei casi il server-side non sostituisce completamente il client-side, ma lo integra. Il modello più efficace è ibrido: alcuni eventi vengono gestiti lato browser, mentre quelli critici per attribuzione e advertising vengono inviati anche tramite server.
Questo approccio riduce la perdita di dati senza compromettere la struttura esistente.
Il server-side tracking è conforme al GDPR?
Il server-side non rende automaticamente un sito conforme al GDPR.
Tuttavia, consente un maggiore controllo sui flussi di dati e sulla gestione dei consensi.
Se progettato correttamente, facilita l’anonimizzazione, il filtering dei parametri sensibili e la governance dei dati prima dell’invio alle piattaforme esterne.
Il server-side aggira gli ad-blocker?
Riduce significativamente l’impatto degli ad-blocker, ma non è un sistema “anti-blocco”.
Poiché i dati vengono inviati dal server e non dal browser, molte estensioni non intercettano la richiesta. Tuttavia, la logica deve essere implementata in modo coerente con la normativa.
Quanto migliora la qualità del dato con il server-side?
Dipende dal settore e dal livello di rifiuto dei cookie. In contesti con 40–50% di perdita dati lato client, il server-side può recuperare una parte significativa dei segnali critici per attribuzione e ottimizzazione advertising, migliorando la coerenza tra traffico reale e misurato.
Il server-side migliora le performance del sito?
Sì. Spostando parte della logica di tracciamento dal browser al server, si riduce il numero di script caricati in pagina. Questo può contribuire a migliorare i tempi di caricamento e il punteggio Core Web Vitals.
Serve Google Tag Manager Server-Side per implementarlo?
Google Tag Manager Server-Side è una delle soluzioni più utilizzate, ma non è l’unica. Esistono implementazioni personalizzate su cloud (ad esempio su infrastrutture proprietarie) o integrazioni dirette con API.
La scelta dipende dall’architettura tecnologica dell’azienda.
Il server-side elimina completamente la modellazione predittiva?
No. Anche con un’infrastruttura server-side rimane una quota di modellazione.
Tuttavia, la dipendenza dai modelli statistici si riduce, perché aumenta la quantità di segnali realmente osservabili.
Il server-side è adatto anche a eCommerce di medie dimensioni?
Sì. Non è una tecnologia riservata alle enterprise.
Per eCommerce che investono in advertising in modo continuativo, il server-side può avere un impatto diretto su ROAS e qualità delle audience.
Qual è la differenza tra Conversion API e server-side tracking?
Le Conversion API (come quelle di Meta o Google) sono uno degli strumenti utilizzabili all’interno di un’architettura server-side.
Il server-side è il modello infrastrutturale; le API sono il canale tecnico attraverso cui vengono inviati i dati.
Il server-side tracking è obbligatorio nel 2026?
Non è obbligatorio per legge, ma è diventato strategicamente necessario per chi investe in performance marketing. In un contesto cookieless e privacy-first, affidarsi esclusivamente al client-side significa accettare una perdita strutturale di dati.
Fonti e riferimenti autorevoli
Google Analytics 4 – Modeling & Consent Mode
Documentazione ufficiale sui modelli predittivi, conversion modeling e gestione dei dati in presenza di consenso limitato.
Google Tag Manager Server-Side
Guida tecnica all’implementazione del tagging server-side su infrastruttura cloud.
Google Privacy Sandbox
Evoluzione dell’ecosistema pubblicitario cookieless e framework per la gestione dei dati anonimizzati.
Apple Intelligent Tracking Prevention
Documentazione tecnica sulle limitazioni ai cookie introdotte da Safari.
Meta Conversion API
Implementazione server-side per l’invio di eventi direttamente ai sistemi pubblicitari Meta.
Regolamento Generale sulla Protezione dei Dati (GDPR)
Quadro normativo europeo sulla protezione dei dati personali.
IAB Transparency & Consent Framework
Standard europeo per la gestione strutturata dei consensi.
Google Core Web Vitals
Linee guida sulle performance e impatto degli script lato browser sull’esperienza utente.
Continua a leggere
17 minuti di lettura

24 minuti di lettura

16 minuti di lettura

E fa consumare meno energia.
Per tornare alla pagina che stavi visitando ti basterà cliccare o scorrere.